

This site (and all other sites hosted on the same server park) have been offline for 72 hours. That’s completely unacceptable, of course, and the underlying fault still isn’t fixed. Here’s what happened.
At 08:45 UTC on January 14, I noticed that my server farm (including falkvinge.net and multiple other websites, as many as you can run on some thirty-odd servers), my main workstation, and the wi-fi in my place was offline. Scrambling to troubleshoot and checking piece by piece, it took me twelve minutes to arrive at the conclusion that my uplink provider was broken – the worst possible scenario, since it means I can’t fix it myself.
The last recorded activity on the server farm had taken place at 08:15 UTC. The event at 08:30 UTC had failed to connect upstream.
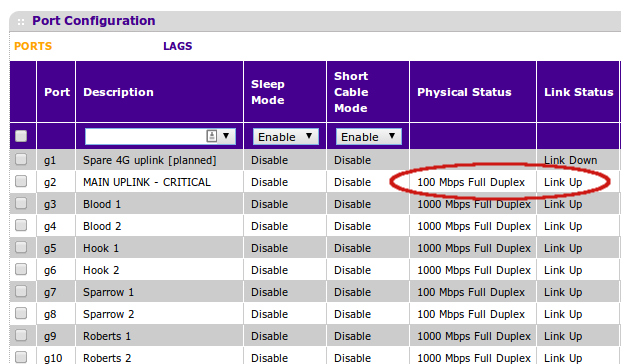
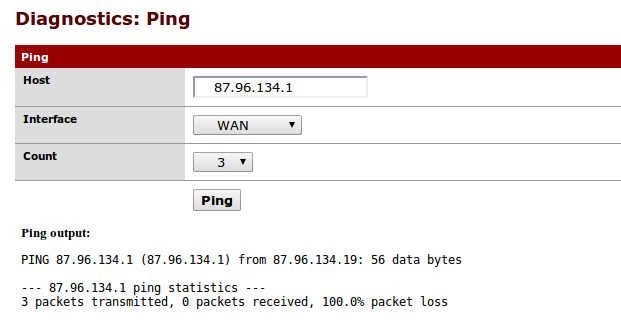
There was a good link to the upstream ISP, but nothing above the link level. I had a good 100Mbit full-duplex connection upstream, but my assigned gateway IP did not respond to pings from the perimeter firewall. Double-checking the physical uplink cable with a laptop (to make sure the switch or firewall weren’t broken) gave the same result.
At this point, I fired up my mobile 4G broadband as a spare way out, so that I could at least communicate with the outside world via laptop and tablet, even if I had lost the ability to publish articles, thoughts, and ideas. (More on that insight in a later article.) I used that 4G connection to file an outage report with my ISP, and I was being quite specific in my troubleshooting (“this is how I know there’s an error, and these are the steps I’ve taken to make sure it’s not in my equipment. By the way, here’s my IP config.”). They wanted my mail address in that outage report. Good thinking, there.

Here’s my mail server. It’s on my balcony. Go right ahead and send me mail to here. By the way, please fix its upstream connectivity first. That will assist the mail in, you know, actually arriving at the server.
After nothing had happened for two hours, I decided to give the techs a voicecall as well. The first tech I spoke to was everything I had hoped for – I was prepared for “have you tried turning it off and on again”-level support, but they apparently saw from my outage report that I was past that level, and the first question was for the MAC address of my perimeter switch or firewall, so they could debug the link to a known endpoint. I was totally not prepared for that level of technical respect, but appreciated it.
However, the tech told me that this can take a while, that they’re submitting a fault ticket to the municipal broadband station and that they will take at least two days. This obviously wasn’t what I wanted to hear. Then, nothing happened for the rest of that day.
The second call to support – on Wednesday – was much less of a joy, where they started by telling me “but you’ve only been offline for a day?”. After I had detonated, explaining not very patiently that downtime is measured in seconds or minutes and not in days, essentially told me that it would take two to five days per round trip to the technical staff, and that he couldn’t care less if I was offline.
These are the times when I’m happy I have my rather large offline music collection, so I’m not totally dependent on Pandora.
I have a blog with a million visits a month, I need that bloody uplink, and this is what I get for fifteen years of continuous custom (yes, I’ve had that fiber uplink since 1999)?
What did they think I was going to do with four static, public IPv4 addresses – that I pay a monthly rent for, nota bene – for a consumer-grade connection? I was outraged, but I was just being stonewalled. I realized no amount of anger would change this person’s mind, and decided to settle for the day.
On Thursday January 16, I woke up with the uplink still down, and figured it would be up by lunch. No joy. Nothing happened at all. I realized that the “two to five business days” was actually intended as serious, and as Thursday’s business day came to a close, I realized that Friday may come and go as well, and if so, this already-unacceptable outage is going to last past the weekend.
The situation just isn’t okay by any measure. So I created a makeshift uplink from spare parts, one that isn’t intended for any kind of long-time use or stability, but one that will work until the primary uplink is restored. On Friday morning, I think I got most of it working, breaking pretty much every best practice in existence, but honoring “if it’s stupid but works, it ain’t stupid”.
If you can read this, then that makeshift uplink – using sort-of mobile 4G broadband, spare homemade antennas and firewall multi-uplink failover configurations – has worked.
Now, for another angry phonecall to my ISP who still haven’t fixed my fiber connection as of 09:00 UTC on Friday Jan 17…


bravo maistore
handy you have such knowledge, Rik. i know who to call when my broadband fails now
not a good attitude from your supplier, but it’s on par with just about every company, over every service or goods today. they think they have got you by the short and curlies and you wont go to another provider, therefore treating you (customers) like crap!
seriously, hope all is good very soon.
In part, I force myself to run my own server park to maintain that knowledge. I don’t want to fall out of touch with the tech I speak about, and this is one way to make sure I don’t.
But the primary reason I run the servers at home is that only I have the key to where they run. If they were somewhere else, I would not be able to guarantee that they weren’t tampered with in some way.
good and sensible precaution, given the amount of privacy that various governments and organisations are doing their best to remove, even destroy! and that includes the EU Commission, who you would think are on the side of EU citizens and industries, rather than the US government and industries
Nice job. If you want something done right, you gotta do it yourself…
If I had a static IP now as for some years ago then I would have a mailserver on a Raspberry Pi or a Odroid U3. But my ISP is blocking port 25 and dynamic IP:s are marked on a list so I would have to use their slow SMTP as relay for outgoing mail.
I empathize, but I can’t really agree with your anger. You’re essentially complaining about getting consumer-level tech support. You may argue that you’re using four static IPs and running a bunch of servers out of your apartment, but I’m guessing that you’re still *paying for* a consumer-grade connection. As we are fond of saying, it’s none of your ISP’s business what you do with your connection – so why should what you do affect the level of tech support you get?
As I saw on Twitter, you’re using AllTele. I took a look at their TOS (for private customers, not businesses), and they do specifically state that you’re not allowed to use the connection for “commercial” purposes (§4.1c, and running 30-odd servers may very well qualify), and they indemnify themselves against any indirect damage caused (so if you’re running a business from home, they are not liable for any lost profit during the time you’re offline).
Essentially, what I’m saying is: Consider this a learning experience. If you’re running something requiring a professional-level Internet connection, don’t use a consumer-level one.
Maybe he should move to chile? There customers are entitled by law to not pay for any number of days their contracted service is down or otherwise unavailable (by demanding the discount of those days from the monthly bill).
That’s pretty standard in Sweden as well. I used to work tech support for a major Swedish ISP (not AllTele though), and our policy was that broadband or TV outage for less than 24 hours did not entitle the customer to compensation (but it was OK to throw them a small bone if they made a fuss, like a bonus non-premium TV channel for a month or so), and outage of over 24 hours up to maybe a week or two was compensated for at 150% (so if your broadband was down for 4 days, we cut 6 days off your next bill). If it was more than that, managers started getting involved.
But we did NOT compensate for anything other than the cost of the service itself. If you’re working from home doing day-trading and make a thousand bucks a day, and can’t do that without the connection, that wasn’t our problem.
Oh, you have AllTele? That explains it.
I have had EXTREMELY bad experiences with them, of course it was “just” a consumer grade (ADSL) connection, but there was always some problem.
If it wasn’t technical, it was with the prices and billing and stuff. It was a long time ago so i don’t remember perfectly, but I think it was them that sometimes took weeks to fix tech problems on their end, and rapidly raising prices, changing the terms of contract renewal constantly, always elongating the minimum time of agreement.
Most companies are about the same, but I think AllTele is among the worst.
May I suggest my father’s line? In the calmest, most pleasant of voices, he would say “Hello, I’m an enraged customer. Please connect me to your escalation manager”
Having been an escalation manager, I know just how terrifying a *nice* smart customer can be (;-))
–dave
This is a very interesting cultural thing. In the States, when people get angry, they SHOW IT AND SHOUT. In contrast, in Sweden and the Nordics, anybody who raises their voice is rude and dismissed out of hand as somebody childish with poor impulse control.
Therefore, when you are enraged in Sweden, you do not raise your voice – to the contrary, you fall back to a very composed, calm, emotionless tone. (Think “Hello, Clarice.”)
When I worked at Microsoft a while back, people from the US were completely unable to deal with getting chewed out by Swedish managers because they would not raise their voice. They would just stand there calmly and emotionlessly explaining what horribly poor performance you had just demonstrated. To an American, this was devastating; it sent the message “you’re so worthless you’re not even worth raising my voice over”.
Very interesting to observe.
You get what you pay for.
And by the way there are plenty of calm US-customers just as there are plenty of enraged manic swedish customers.
Those Ikea server racks are just great 🙂
I’ve been waiting for a fiber in my new apartment for 3 months now. The current ISP is giving me the crappiest speeds for a while and the one I’ve been waiting delivers awesomely good service (at least for now) in the other place I had it installed. There is a physical issue preventing them from bringing the fiber in so they had to make a project to fix it and stuff. Took them 3 months (already scheduled installation, finally). Sure their customer service was very polite and kept me informed along with many apologies but I know the feeling of needing the connection while it does not live to your expectations. Can be infuriating indeed. The bright part is that this new ISP is adding competition (along with other 2 new ones in the region) so things should get better. In fact I’m assuming the delay is exactly due to people fed up with the current 2 dominant ones that offer terribly crappy experiences and leaving in droves to the new ones.